
یک درخواست مخرب مسدود میشود، در حالی که ده درخواست از راه میگذرند. این شکاف تفاوت بین گذراندن بنچمارکها و مقاومت در برابر حملات دنیای واقعی را تعریف میکند – و شکافی است که بیشتر شرکتها وجود آن را نمیدانند.
هنگامی که مهاجمان یک درخواست مخرب واحد ارسال میکنند، مدلهای هوش مصنوعی منبع باز (Open-Weight) به خوبی عمل کرده و ۸۷٪ از حملات را مسدود میکنند (به طور متوسط). اما زمانی که همان مهاجمان چندین درخواست را در طول یک مکالمه از طریق کاوش، بازسازی و تشدید در چندین تبادل ارسال میکنند، محاسبات به سرعت معکوس میشوند. نرخ موفقیت حملات از ۱۳٪ به ۹۲٪ افزایش مییابد.
برای مدیران ارشد اطلاعات (CISOs) که در حال ارزیابی مدلهای منبع باز برای استقرار سازمانی هستند، این پیامدها فوری هستند: مدلهایی که قدرت چتباتهای مشتریمحور، همکاران داخلی و عاملهای خودکار شما را تامین میکنند ممکن است بنچمارکهای ایمنی تکمرحلهای را پشت سر بگذارند در حالی که تحت فشار مداوم حملات خصمانه به طور فاجعهباری شکست میخورند.
«بسیاری از این مدلها شروع به کمی بهتر شدن کردهاند،» دیجی سمپث، معاون ارشد اجرایی گروه پلتفرم نرمافزاری هوش مصنوعی سیسکو (Cisco) به VentureBeat گفت. «هنگامی که شما یک بار به آن حمله میکنید، با حملات تکمرحلهای، آنها قادرند از خود محافظت کنند. اما زمانی که از تکمرحلهای به چند مرحلهای میروید، ناگهان این مدلها شروع به نشان دادن آسیبپذیریهایی میکنند که حملات در حال موفقیت هستند، گاهی اوقات نزدیک به ۸۰٪.»
تیم تحقیقات و امنیت تهدید هوش مصنوعی سیسکو دریافتند که مدلهای منبع باز که حملات تکمرحلهای را مسدود میکنند، تحت وزن پایداری مکالمه فرو میپاشند. مطالعهی آنها که اخیراً منتشر شده است نشان میدهد که نرخ موفقیت جیلبریک (Jailbreak) تقریباً ده برابر افزایش مییابد زمانی که مهاجمان گفتگو را طولانیتر میکنند.
یافتهها، منتشر شده در «مرگ با هزاران درخواست: تحلیل آسیبپذیری مدلهای منبع باز» توسط ایمی چانگ، نیکلاس کانلی، هاریش سانثانا لاکشمي گِسان و آدام سوواندا، آنچه را که بسیاری از محققان امنیت مدتها مشاهده کردهاند و مشکوک بودهاند، اما نمیتوانستند آن را در مقیاس بزرگ اثبات کنند، کمیسازی میکند.
اما تحقیقات سیسکو این موضوع را نشان میدهد و ثابت میکند که رفتار حملات چند مرحلهای به عنوان یک گسترش از آسیبپذیریهای تکمرحلهای اشتباه است. شکاف بین آنها کیفی (qualitative) نیست، بلکه مسئلهای از درجه (degree) است.
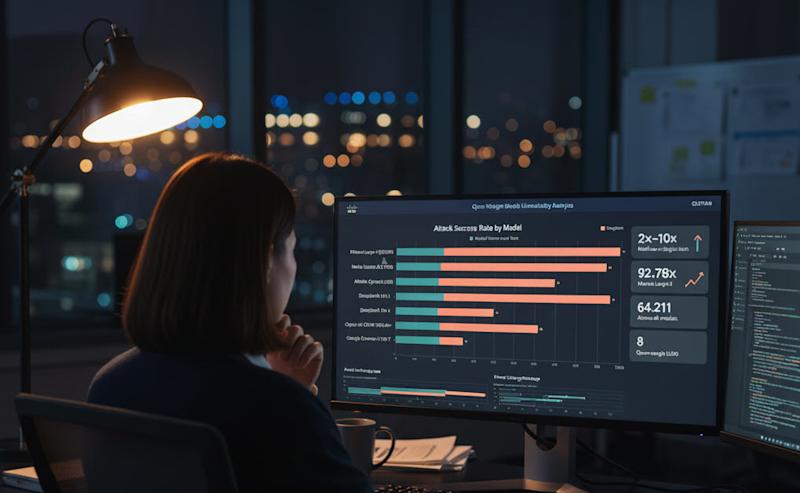
تیم تحقیقات هشت مدل منبع باز را ارزیابی کرد: علی بابا (Qwen3-32B)، دیپسیک (v3.1)، گوگل (Gemma 3-1B-IT)، متا (Llama 3.3-70B-Instruct)، مایکروسافت (Phi-4)، میسترال (Large-2)، اپنایآی (GPT-OSS-20b) و ژیپو ایآی (GLM 4.5-Air). با استفاده از روش جعبه سیاه – یا آزمایش بدون دانش معماری داخلی، که دقیقاً همانطور که مهاجمان دنیای واقعی عمل میکنند – تیم موفقیت حملات را هنگام جایگزینی تهاجم تکشاتی اندازهگیری کرد.
محققان خاطرنشان میکنند: «نرخهای موفقیت حمله تکمرحلهای (ASR) به طور متوسط ۱۳.۱۱٪ است، زیرا مدلها میتوانند به راحتی ورودیهای خصمانه جداگانه را تشخیص داده و رد کنند. در مقابل، حملات چند مرحلهای که از پایداری مکالمه استفاده میکنند، میانگین ASR برابر با ۶۴.۲۱٪ را به دست میآورند [افزایشی ۵ برابری]، با مدلهایی مانند علی بابا Qwen3-32B که به ASR 86.18٪ و میسترال Large-2 که به ASR 92.78٪ میرسد.» این افزایش ۲۱.۹۷٪ نسبت به یک حمله تکمرحلهای بود.
تیم تحقیقات مقاله، دیدگاهی موجز در مورد انعطافپذیری مدلهای منبع باز در برابر حملات ارائه میدهد: «این تشدید، از ۲ تا ۱۰ برابر است و ناشی از عدم توانایی مدلها برای حفظ دفاعهای مبتنی بر زمینه در طول گفتگوهای طولانی مدت است که به مهاجمان اجازه میدهد درخواستها را اصلاح کرده و اقدامات امنیتی را دور بزنند.»
[تصویر ۱: نرخ موفقیت حمله تکمرحلهای (آبی) در مقابل نرخ موفقیت حمله چند مرحلهای (قرمز) در تمام هشت مدل آزمایش شده. شکاف از ۱۰ درصد نقطه (گوگل Gemma) تا بیش از ۷۰ درصد نقطه (Mistral، Llama، Qwen) متغیر است. منبع: Cisco AI Defense]
تیم تحقیقات پنج استراتژی حمله چند مرحلهای را آزمایش کرد که هر کدام جنبهای مختلفی از پایداری مکالمه را بهرهبرداری میکردند:
- تجزیه و تجدید ترکیب اطلاعات: درخواستهای مضر را به اجزای بیضرر در طول چندین نوبت разбивает و سپس آنها را دوباره تجدید میکند. این تکنیک با موفقیت ۹۵٪ علیه میسترال Large-2 به دست آورد.
- ابهام معنایی: چارچوب مبهمی را که دستهبندیهای ایمنی را گیج میکند، معرفی میکند و به موفقیت ۹۴.۷۸٪ در برابر میسترال Large-2 میرسد.
- حملات crescendo: درخواستها را به تدریج در طول چندین نوبت افزایش میدهد و از بیضرر شروع شده و به مضر ختم میشود، که با موفقیت ۹۲.۶۹٪ در برابر میسترال Large-2 دست یافت.
- نقشآفرینی و پذیرش شخصیت: زمینههای داستانی را ایجاد میکند که خروجیهای مضر را نرمالسازی میکنند، تا ۹۲.۴۴٪ موفقیت در برابر میسترال Large-2 به دست میآورند.
- بازسازی امتناع: درخواستهای رد شده را با توجیهات مختلف دوباره بستهبندی میکند تا زمانی که یکی از آنها موفق شود و به موفقیت ۸۹.۱۵٪ در برابر میسترال Large-2 برسد.
آنچه این تکنیکها را موثر میکند، پیچیدگی نیست، بلکه آشنایی است. آنها شبیه نحوه مکالمه طبیعی انسانها هستند: ایجاد زمینه، روشنسازی درخواستها و بازسازی هنگام شکست رویکردهای اولیه. مدلها در برابر حملات عجیب و غریب آسیبپذیر نیستند. آنها مستعد خود پایداری هستند.
[جدول ۲: نرخ موفقیت حمله بر اساس تکنیک در تمام مدلها. سازگاری در سراسر تکنیکها به این معنی است که سازمانها نمیتوانند با دفاع از فقط یک الگو، از حملات جلوگیری کنند. منبع: Cisco AI Defense]
این تحقیق در یک نقطه عطف بحرانی زمانی میرسد که متنباز به طور فزایندهای به امنیت سایبری کمک میکند. مدلهای متنباز و وزنباز به سنگ بنای نوآوری صنعت امنیت سایبری تبدیل شدهاند. از تسریع زمان عرضه بازار استارتآپها گرفته تا کاهش وابستگی فروشنده در سطح سازمانی و فعال کردن سفارشیسازی که مدلهای اختصاصی نمیتوانند مطابقت دهند، متنباز به عنوان پلتفرم ترجیحی اکثر استارتآپهای امنیت سایبری دیده میشود.
این پارادوکس بر سیستو نیز از دست نرفته است. خود مدل Foundation-Sec-8B شرکت، که برای برنامههای کاربردی امنیتی طراحی شده است، به عنوان وزنهای باز در Hugging Face توزیع میشود. سیستو فقط انتقاد از مدلهای رقبا را ندارد. این شرکت به یک آسیبپذیری سیستماتیک را تشخیص میدهد که بر کل اکوسیستم وزنباز تأثیر میگذارد، از جمله مدلهایی که خود آنها منتشر میکنند. پیام این نیست که
📌 توجه: این مطلب از منابع بینالمللی ترجمه و بازنویسی شده است.